计算机组成原理 & 体系结构
Last-Modified:2025/6/26
Week1:绪论(chap1)
为什么学习计算机组成原理?
“若想理解一个算法为什么是不可行的,或者理解一个可行的算法为什么运行太慢,你必须能够从计算机的观点来看这个程序。”
- 计算机体系结构,集中于计算机体系结构和行为的研究,是从程序员的角度看到的系统实现的逻辑和抽象。
- 指令集架构,ISA是机器上运行的软件与执行软件的硬件之间共同认可的接口,ISA允许你与机器进行对话。
硬件和软件等价原理:
任何由软件完成的任务也能使用硬件完成,并且任何直接由硬件完成的操作也可以使用软件完成。
摩尔定律:
硅芯片的密度每18个月就会翻一番。
罗克定律:建立半导体工厂的主要设备的成本每四年就翻一番。
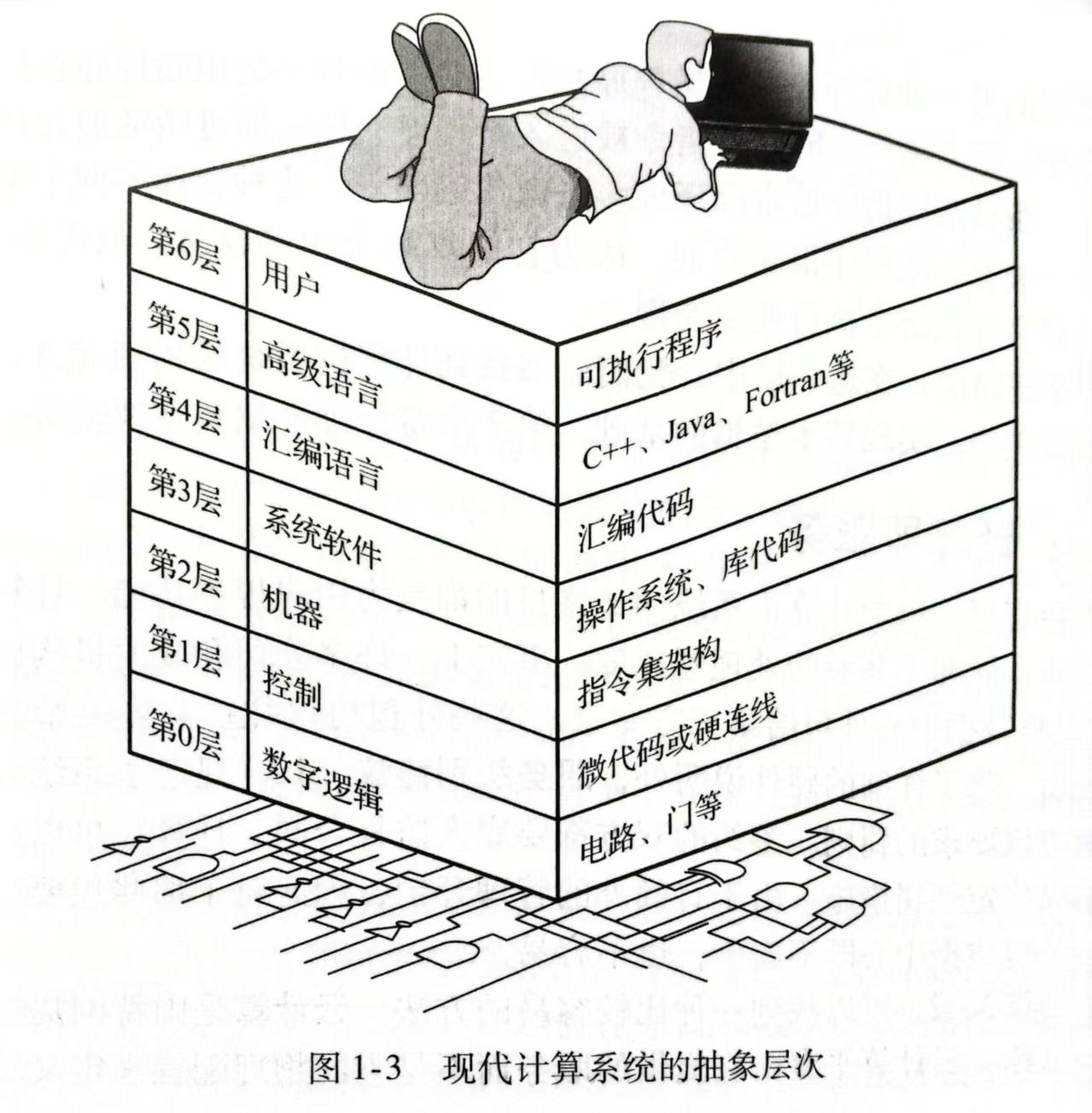
计算机层次结构
通过抽象原理,把机器的构造想象为由不同的层次构成,每一层都有自己的特殊指令集,再需要的时候要求下层机器执行任务。
Week2:计算机系统中的数据表示
计数系统:
一个数,都可以根据唯一展开法,表述成n的幂次的一个多项式,其中的系数就是这个数的n进制表示。
将这个原理推广到小数,用n的负幂次的多项式表示小数部分。
整数表示:
有符号:
正数的原码、反码、补码相同,负数的补码就是在原码基础上,符号位不变,按位取反再加1。
具体的原理取决于加法器的硬件设计。
进位和溢出
对于确定进位何时表示错误的方法取决于使用的是有符号数还是无符号数。
对于无符号数,一个进位(从最左边出来的)表示位的总数不够大不足以保存结果值,并发生溢出。
对于有符号数,如果进入符号位和从符号位出来的进位不同,则发生溢出。
进位和溢出彼此独立地发生。
浮点数表示:
科学计数法简化了非常大或非常小的数字的手算过程。它也是当今数字计算机中浮点运算的基础。
不同于连续的实数域,计算机是带有有限存储空间的有限系统。当我们让计算机执行浮点运算时,我们是在有限的整数系统中对实数的无限系统建模。
浮点数由三部分组成:符号位、指数部分、小数部分(尾数/有效数)。
由于这种方式无法唯一地表示每一个数字,IEEE-754将浮点数规范——隐含1
这种方式有以下好处和缺点:
- 规范化
- 获得了额外的一位精度
- 无法表示0
因此——IEEE-754对一些特殊的数的表示进行了规定,并采取127的指数移码。
浮点数可以完全工作的原理是:在这个范围内总会有一个数接近你想要的数。
表数范围、准确度、精度
注意浮点数的表数范围——有两个上界和下界
准确度必须放在上下文中
更高的精度通常使值更准确,但并不总是这样。
浮点数运算问题
浮点数运算不具备分配律和结合律
浮点数的舍入问题可以传播,并导致实质问题——因此避免在for循环,while循环中对浮点数进行运算
最好的做法是声明接近,比如epsilon=0.000001,if(abs(x-1) < epsilon)then……
这里也可以发现浮点二分算法要这样写的原因。
“对浮点异常深刻的理解可以毫不夸张地说就是在保护生命。“
字符编码
EBCDIC
在硬件之间传输数据——EBCDIC
二进制编码的十进制(BCD)能够降低错误率——详见数电,因此在电子学中非常普遍。
为了保持与早期计算机和外围设备的兼容性并拓展计算机的性能,IBM工程师将BCD由6位扩展到8位。得到EBCDIC
ASCII
在系统之间传输数据——ASCII(美国信息交换标准码)
ASCII定义了32个控制字符的代码、10位数字、52个字母、32个特殊字符和空格字符。高阶位用于奇偶校验。
奇偶校验是所有错误检测方案中最基本的。
Unicode
在不同语言之间的字符表示——Unicode
错误检测与纠错
随着传输速率的增加,位传输更紧密,要实现完全无错误,在物理上是不可能的。
ASCII字节中的奇偶校验码只能检测到字节中的奇数个错误。如果发生两个错误,我们无法检测出。
循环冗余校验(CRC)——错误检测编码
循环冗余校验是一种校验和,校验和用于各种各样的编码系统——从条形码到国际标准图书编号——都是自检码。
循环和循环冗余校验是两种类型的系统错误检测方案——错误检查位被附加到原始信息字节上了。
计算和使用CRC是这里一大考点。
汉明码——错误恢复编码
在数据通信中,只要有错误检测的能力就可以
在磁盘系统中,存储设备和主存必须具备不仅可以检测还能纠正一定数量错误的能力。
汉明距离是指在两个码字中有多少位不同。
一个编码系统的错误检测和纠正能力取决于最小汉明距离D(min)
Week3:一个简单的计算机模型MARIE
第一章:计算机系统进行了总体概述
第二章:数据表示方法以及存储处理方法
第三章:数字电路的基本组成成分
现在,组合这些背景知识,讨论一个直观简单的计算机模型=>MARIE=>Machine Architecture that is Really Intuitive and Easy
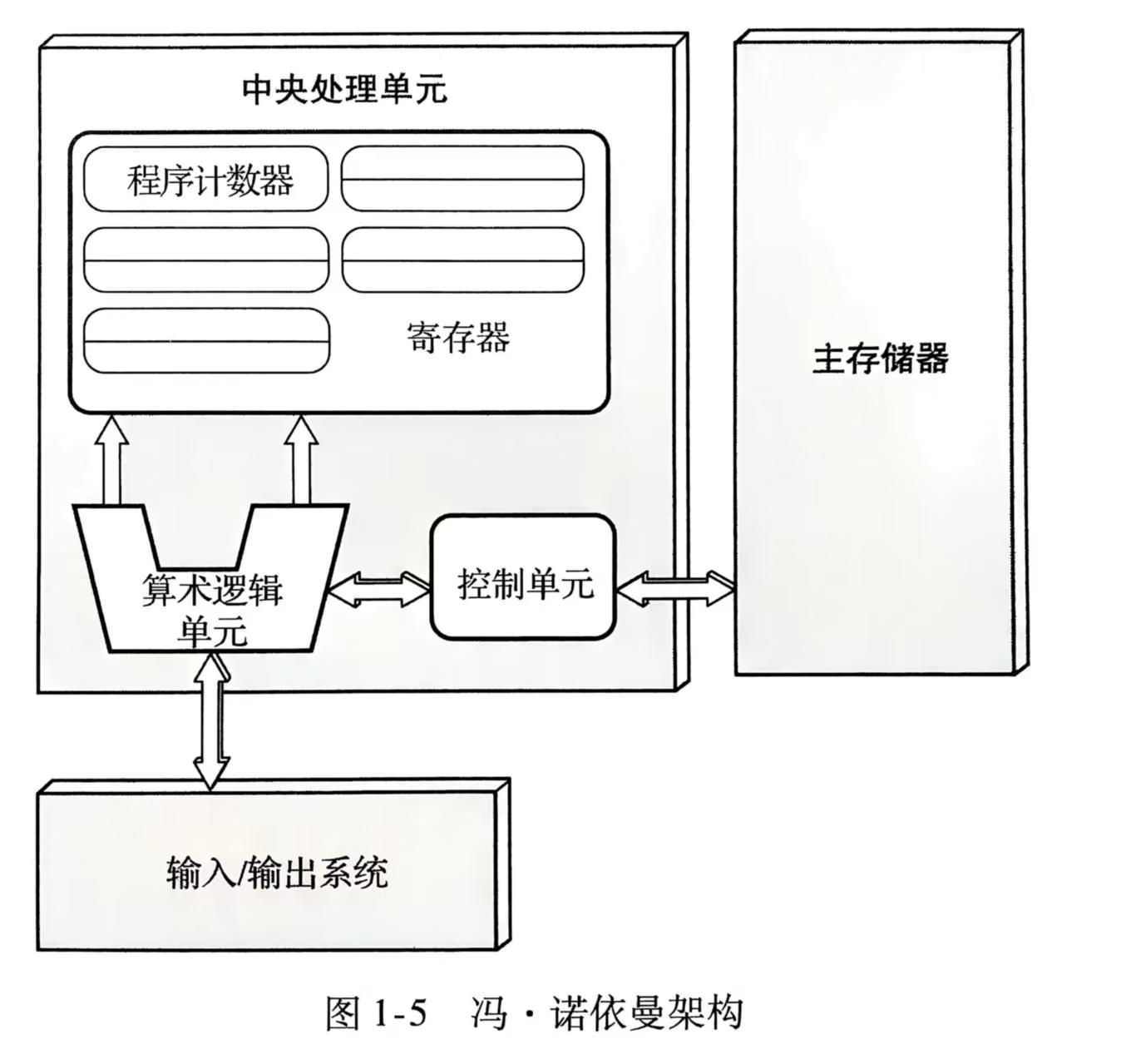
CPU基本知识和组织结构
CPU由两部分组成:
数据通路——一个由存储单元和算术逻辑单元组成的网络
控制单元——对各种操作进行控制的结构
关于总线仲裁机制
- 1.菊花链仲裁方式(Daisy chain arbitration)
设计使用一个“总线允许”控制线,该总线是从最高优先级设备传给最低优先级。 - 2.集中式并行仲裁(centralized parallel arbitration)
每个设备都有个到总线的请求控制线和一个选择谁可以用总线的仲裁控制器。(可能导致瓶颈) - 3.自选择的分配式仲裁(Distributed arbitration using self-selection)
类似于集中仲裁,但不是通过中央控制器选择,而是设备本身决定谁具有最高优先级。 - 4.冲突检测的分配式仲裁(distributed arbitration using collision detection)
允许每个设备对总线发起请求。如果总线检测到任何冲突,设备必须发送另一个请求。(以太网使用这种方式)
关于存储器的寻址方式-交叉存储器
单个存储器模块只能串行访问(每次只能执行一次存储器访问)。交叉存储器可以缓解这个问题,它把存储器分成多个存储模块。,
其中多个模块可以同时访问。
在低位交叉,地址的低位用于选择模块;在高位交叉时,使用地址的高位选择模块。
<div class="fold"> <div class="fold-title fold-info collapsed" data-toggle="collapse" href="#collapse-7d8541c9" role="button" aria-expanded="false" aria-controls="collapse-7d8541c9"> <div class="fold-arrow">▶</div>对齐 </div> <div class="fold-collapse collapse" id="collapse-7d8541c9"> <div class="fold-content"> <p>现在,终于可以懂得原理了!<br><strong>如果计算机采用按字节编址的体系结构,并且指令系统的结构字长大于一字节,则必须解决对其的问题。</strong><br>这个问题本应在C语言程序设计中被讲到,具体来说就是长一些的结构体需要注意对其问题。<br>后来遇到是在计算机学院的问题求解实践课上,老师特别强调了对齐问题,很多大的项目不明原因崩溃最大问题之一——对其。</p><p>“例如,如果我们希望在按字节编址的计算机上读取32位长的字,我们必须确保字存储在自然对齐的边界上,并且访问从该边界开始。在字长32位的情况下,这是通过使地址为4的倍数来实现的。”<br>可以发现,C语言的运行表现是和机器类型直接相关的。编程时要特别注意。</p> </div> </div></div>指令的执行:
取指-译码-执行周期是计算机在运行程序时执行的一系列步骤
- 首先,我们需要从内存中取指令,并将其放入指令寄存器(IR)中。
- 一旦指令进入IR,它将被译码以确定接下来需要做什么。
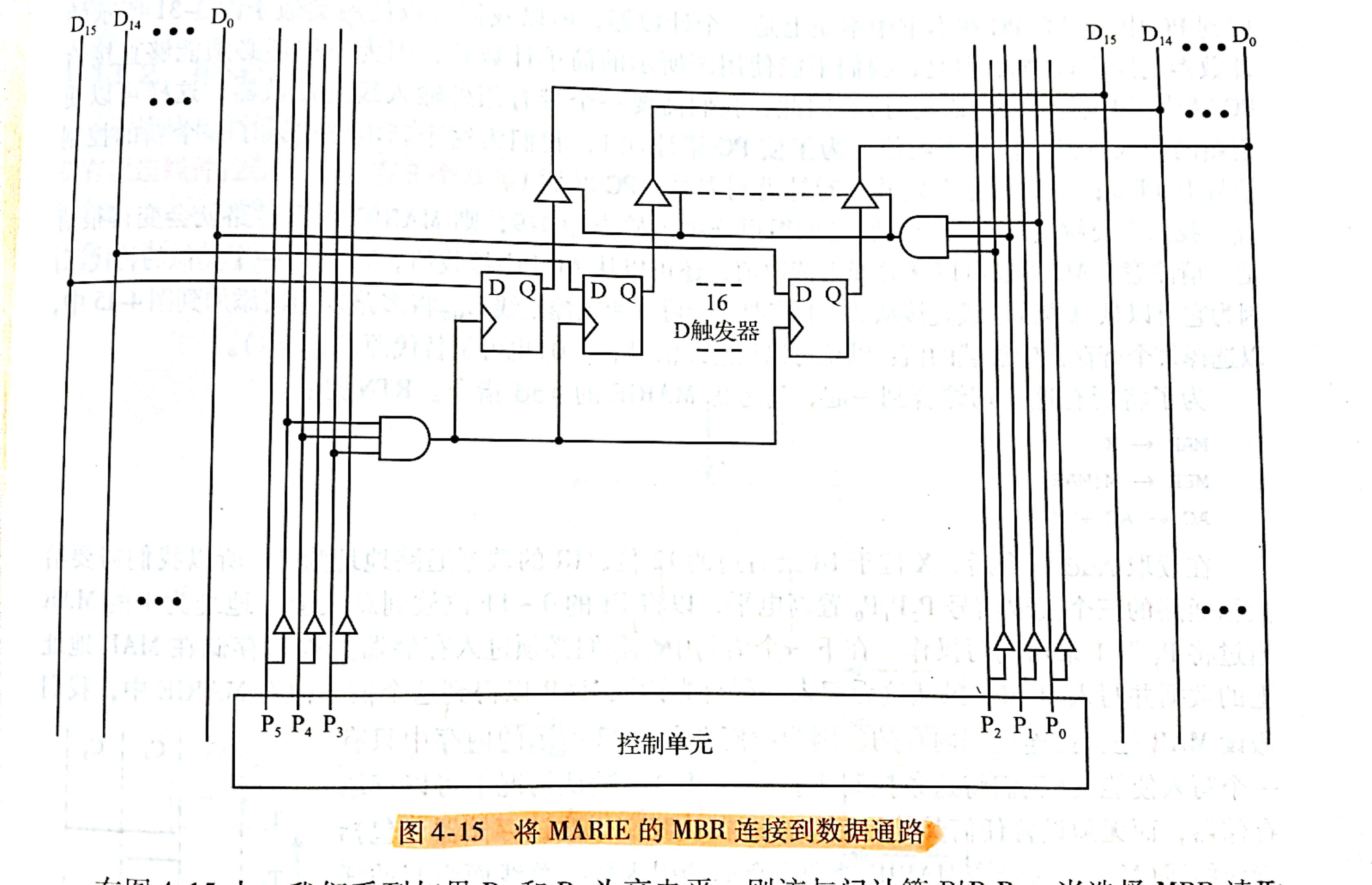
- 如果操作涉及内存值(操作数),则将其检索并放入内存缓冲寄存器(MBR)中。
- 当所有内容就绪后,指令被执行。
中断:
由用户或系统发出的中断请求可以是可屏蔽中断(可以被禁止或忽略)或不可屏蔽中断,它可以在指令内或指令间发生,可以是同步(每次执行的同一位置)的也可以是异步(意外的)的。
不可屏蔽的中断是那些为了是系统保持稳定运行所必须被执行的。
Week4:MARIE模型
MARIE
MARIE 表示一个真正直观和简单的计算机体系结构。它包括存储程序和数据的 CPU(由一个 ALU 和几个寄存器组成)。它具有真正工作的计算机所必需的功能部件。
MARIE 具有下列特点:
- 使用二进制数和补码表示法
- 存储程序和采用固定的字长
- 指令(不是按字节的)编址
- 主存储器的容量为 4K 字(即每个地址需要使用 12 位二进制数)
- 16 位数据(16 位字)
- 16 位指令:4 位操作码和 12 位地址
- 一个 16 位的累加器(AC)
- 一个 16 位的指令寄存器(IR)
- 一个 16 位的存储器缓冲寄存器(MBR)
- 一个 12 位的程序计数器(PC)
- 一个 12 位的存储器地址寄存器(MAR)
- 一个 8 位的输入寄存器
- 一个 8 位的输出寄存器
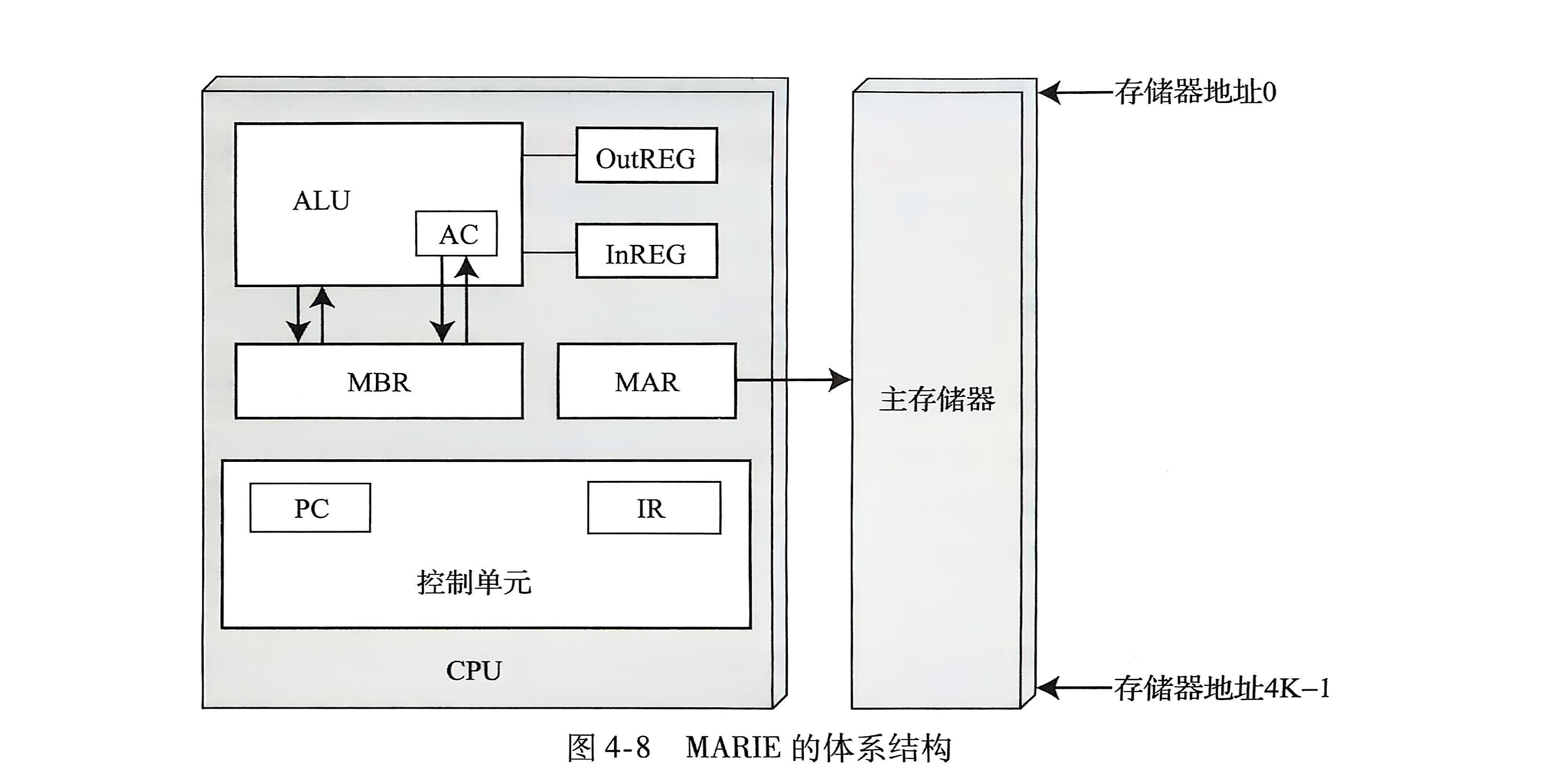
这节课主要是图太多,PPT轮播感觉起来有点乱,把图放一起就有了整体架构。



处理器指令集架构(ISA)
ISA指定了计算机可以执行的指令及其格式。ISA本质上是软件和硬件之间的接口。
大多数ISA包含的指令有:处理数据的指令、移动数据的指令和控制程序执行顺序的指令。
以MARIE举例,
“可以执行的指令的格式”:16位的指令,高4位是操作码,低12位是地址:
“可执行指令的样子”:
可以发现:
- 处理数据的指令:Add Subt Input Output
- 移动数据的指令:Load Store
- 控制程序执行顺序的指令:Skipcond Jump
寄存器传输表示(RTN)
Load指令将内容加载到存储器,但是要观察在部件级发生了什么,可以发现一系列微操作——微指令。
微指令规定了对寄存器中存储的数据执行的基本操作
描述微操作行为的符号表示法称为——寄存器传输表示法(RTN),或寄存器传输语言(RTL)
用RTN表示程序执行过程是本章重点
汇编语言与编译程序
了解怎样利用汇编语言编程有助于很好地理解计算机的体系结构
指令集的扩展
刚刚列出的MARIE的指令集足以编写任何所需的程序,但我们可以再增加几条指令使MARIE的编程任务更加简单
使用:ADDI,JumpI,LoadI,StoreI引入了不同的寻址模型:直接寻址和间接寻址
硬连线和微程序控制
MARIE执行add指令时,控制信号将ALU设置为加法运算,并将结果放到AC中。
ALU具有不同的控制线,它们可以决定执行哪一种操作——这些控制线实际上是如何被选中的?
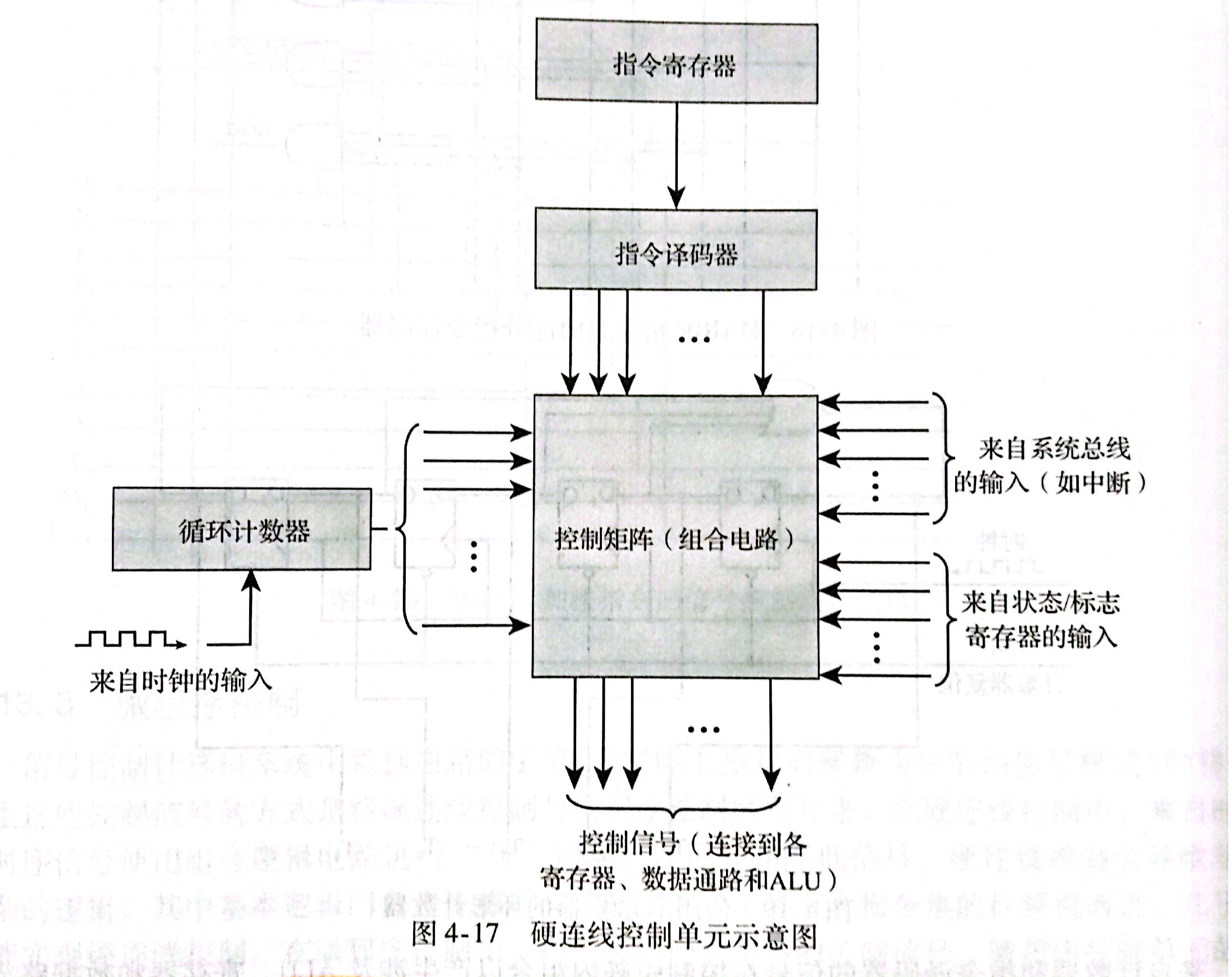
- 硬连线控制
物理上将各条控制线与实际的机器指令连接。一般来说,指令被分成不同的字段,字段中不同的位连线接到输入线,来驱动不同的数字逻辑不见。 - 微程序控制
使用由微指令组成的软件,它们执行指令的微操作。
机器执行
这里虽然不是考点,但是打通了对“第0层:数字逻辑,第1层:控制,第2层:机器”的认识。
结合之前学过的数字电路逻辑,想明白一条计算机指令是如何通过高电平,低电平……实现的。
这里把前边的那几张图拼起来,做一个本章的小结:

所以说:
Q:为什么计算机需要时钟周期?
A:因为计算机需要循环计数器来产生控制信号,而计数器需要时钟信号输入。
Q:为什么计算机需要循环计数器来产生控制信号?
A:执行一条指令需要让寄存器等按顺序执行一系列操作,而这个固定的顺序需要基于一个不断重复的时钟周期序列,且序列的每个信号都不同。
这也解释了:不同信号的数量由最大微操作数量确定。
这也解释了:一个微处理器每秒能够执行的指令数与它的时钟速度成正比例关系。
这也解释了:计算机的运行速度与微处理器的脉冲频率(时钟周期)直接相关,处理器的额定频率是整个系统速度的关键。
如本书一开篇提出的:软件与硬件等价原理
硬连接做到的事用微程序也做到了,但是两者在性能,扩展性,成本上各有优劣,学习计组也是在学习如何在其中TradeOff。
CISC和RISC是处理器指令集架构的两种主要设计思想
CISC的具体实现:x86架构,RISC-V, IBM System/360 和 System/370……
- x86架构:Intel和AMD是x86架构处理器市场的主导者。
RISC的具体实现:ARM架构,MIPS架构……
- ARM架构:它以低功耗、高性能和高能效比著称,广泛应用于移动设备、嵌入式系统和物联网设备。随着苹果M系列芯片的成功,ARM架构在PC市场的份额逐渐增加。 ▶ARM架构的起源
ARM架构的起源可以追溯到20世纪80年代初,由英国的Acorn Computers公司开发。当时,Acorn Computers的工程师团队,包括Steve Furber和Sophie Wilson,基于加州大学伯克利分校的RISC(精简指令集计算机)研究成果,设计出了第一款ARM处理器——ARM1。这款处理器于1985年推出,是世界上首款商业化的RISC处理器之一。
1990年,Acorn Computers与苹果公司(Apple)和VLSI Technology共同投资成立了Advanced RISC Machines Ltd.(ARM公司),专注于ARM架构的进一步开发和推广。ARM公司采用IP授权模式,允许其他半导体公司使用其架构设计芯片,这种模式为ARM架构的广泛应用奠定了基础。
ARM架构因其高效能、低功耗和灵活可扩展的特点,逐渐在移动设备、嵌入式系统和物联网领域占据主导地位。
- MIPS架构:
指令简单且长度固定,采用流水线技术提高执行效率,硬件设计简洁。
要用于嵌入式系统、网络设备和个人娱乐装置等,以低功耗、高性能和良好的扩展性著称。
<div class="fold"> <div class="fold-title fold-info collapsed" data-toggle="collapse" href="#collapse-ec54af65" role="button" aria-expanded="false" aria-controls="collapse-ec54af65"> <div class="fold-arrow">▶</div>龙芯 </div> <div class="fold-collapse collapse" id="collapse-ec54af65"> <div class="fold-content"> <p>龙芯等厂商通过获得MIPS架构授权,开发了自主可控的处理器,并逐步形成了自己的指令集架构(如LoongArch),以提高自主性和安全性。<br>我们学院学长们留下的操作系统:LoOS就是基于龙芯的指令集架构开发的。</p> </div> </div></div><div class="fold"> <div class="fold-title fold-info collapsed" data-toggle="collapse" href="#collapse-3497ebb4" role="button" aria-expanded="false" aria-controls="collapse-3497ebb4"> <div class="fold-arrow">▶</div>RISC-V </div> <div class="fold-collapse collapse" id="collapse-3497ebb4"> <div class="fold-content"> <p><strong>RISC-V与x86架构的对比</strong></p><ul><li>开放性:<br>RISC-V:完全开源,任何人都可以免费使用、修改和分发。<br>x86:由英特尔和AMD主导,技术授权严格,需要支付授权费用。</li><li>灵活性:<br>RISC-V:指令集简洁,可扩展性强,可以根据不同应用场景进行定制。<br>x86:指令集复杂,扩展性较差,定制化难度较高。</li><li>应用场景:<br>RISC-V:广泛应用于物联网、嵌入式系统、人工智能、高性能计算等领域。<br>x86:主要用于个人电脑、服务器和数据中心,以高性能和强大的计算能力著称。<br>RISC-V的应用领域</li><li>物联网:RISC-V芯片满足低功耗、低成本、小尺寸需求,适用于智能家居设备、可穿戴设备等。</li><li>边缘计算:在本地快速处理数据,减少云端传输,适用于智能安防摄像头、车载系统等。</li><li>人工智能:RISC-V可以通过定制化优化AI计算需求,例如阿里巴巴达摩院研发的AI专用RISC-V处理器C908X。</li><li>高性能计算:RISC-V正在向高性能计算领域拓展,例如玄铁C930处理器已用于服务器和自动驾驶汽车。<br>RISC-V的未来发展<br>预计到2030年,RISC-V处理器的出货量将达到170亿颗,占据全球市场近25%的份额。<br><strong>RISC-V有望在高性能计算、人工智能和物联网等领域与x86和ARM架构形成三分天下的局面。</strong><br>RISC-V的开放性和灵活性使其成为全球科技产业的重要一环,特别是在中国,RISC-V被视为芯片自主可控的重要突破口。</li></ul> </div> </div></div><div class="fold"> <div class="fold-title fold-info collapsed" data-toggle="collapse" href="#collapse-cef6d94b" role="button" aria-expanded="false" aria-controls="collapse-cef6d94b"> <div class="fold-arrow">▶</div>x86架构的发展与CISC理念的演变 </div> <div class="fold-collapse collapse" id="collapse-cef6d94b"> <div class="fold-content"> <ul><li>早期CISC设计:在x86架构的早期阶段(如8086、80286),它完全符合CISC架构的特点,指令集复杂且硬件实现复杂。</li><li>微操作和解码:随着技术的发展,x86架构逐渐引入了微操作(microcode)来简化复杂指令的执行。微操作是一种低级的指令,用于将复杂的CISC指令分解为多个简单的操作。</li><li>现代x86处理器的优化:现代x86处理器(如英特尔的酷睿系列和AMD的锐龙系列)虽然仍然保留了CISC架构的指令集,但在内部实现上采用了RISC(精简指令集计算机)的设计思想。例如,复杂的x86指令在内部被转换为多个简单的微操作,这些微操作在硬件上以类似RISC的方式执行。</li><li>混合架构:现代x86处理器可以被视为一种混合架构,它在外部保持CISC指令集的兼容性,而在内部则采用了RISC的设计理念来提高性能和效率。</li></ul> </div> </div></div><div class="fold"> <div class="fold-title fold-info collapsed" data-toggle="collapse" href="#collapse-a58f177e" role="button" aria-expanded="false" aria-controls="collapse-a58f177e"> <div class="fold-arrow">▶</div>NachOS和MIPS </div> <div class="fold-collapse collapse" id="collapse-a58f177e"> <div class="fold-content"> <p>NachOS和MIPS之间的关系主要体现在以下几个方面:</p><p><strong>MIPS模拟器</strong><br>NachOS包含一个MIPS指令集的模拟器,用于模拟MIPS架构的处理器。这个模拟器允许用户级程序在NachOS环境中运行,而无需依赖真实的MIPS硬件。用户程序被加载到模拟器的内存中,模拟器初始化寄存器后开始执行。</p><p><strong>用户程序与内核模式</strong><br>NachOS有两种执行模式:</p><ul><li><strong>用户模式</strong>:用户程序在MIPS模拟器中运行,只能访问与模拟机器相关联的内存。</li><li><strong>内核模式</strong>:当用户程序执行导致硬件陷阱(如非法指令、页面错误、系统调用等)时,NachOS切换到内核模式,执行内核代码。</li></ul><p><strong>系统调用与参数传递</strong><br>在基于MIPS架构的NachOS中,系统调用的参数传递通常通过寄存器完成。例如,<code>Exec()</code>系统调用的参数<code>FileName</code>需要从用户地址空间传递到内核中,通常会将参数依次保存到寄存器<code>$4-$7</code>中。</p><p><strong>跨平台支持</strong><br>尽管NachOS最初是为MIPS架构设计的,但它也支持其他平台(如SPARC、PA-RISC、x86等)。不过,用户程序仍然需要编译为MIPS指令集的代码,以便在NachOS的MIPS模拟器中运行。</p><p><strong>教学用途</strong><br>NachOS是一个教学级操作系统,主要用于操作系统课程的教学实验。通过使用MIPS模拟器,学生可以在不依赖真实硬件的情况下,学习和实验操作系统的基本原理。</p><p>总结来说,MIPS架构在NachOS中主要通过模拟器实现,用于运行用户程序并支持系统调用的执行,是NachOS教学和实验环境的重要组成部分。</p> </div> </div></div>[More Information]
MARIE体系结构总结与对比
CISC与RISC:Intel和MIPS体系结构
MIPS编程
Week5:仔细审视指令集架构
大多数RISC架构的计算机采用大端的方式
CPU内部的存储:堆栈和寄存器
- 堆栈型架构
- 累加器型架构
- 通用寄存器(GPR)型架构
GPR分类:
- 存储器-存储器
- 寄存器-存储器
- 取-存架构
操作数个数和指令长度
- 定长指令
浪费空间但速度快,当使用指令集流水线时,它具有更优的性能。 - 变长指令
译码更复杂但是节省存储空间。
在需要一套丰富的操作码的需求和希望获得短指令的愿望之间,扩展操作码给出了一个折中的方案。
扩展操作码:在定长指令中操作数的个数并非固定不变,我们可以设计一个有足够长度且长度固定的指令集架构,但允许操作数字段的位数是可变的。
寻址
- 立即寻址:
- 直接寻址:
- 寄存器寻址:
- 间接寻址:
- 寄存器间接寻址:
- 变址寻址:
Week6:
Week7:
Week8:
Week9:
Week10:
Week11:
Week12:
Week13:
Week14:
Week15:
Week16:
期末复习
推荐资料:
- 王道《2026年计算机组成原理考研复习指导》
- 如果是面向期末考试还是推荐看ppt
第一章:计算机系统概述
- MAR和MBR虽然是存储器的一部分,但在现代计算机中确实存在于CPU中的。
- 因为内存和CPU之间存在着操作速度上的差别,所以必须使用地址寄存器来保存地址信息
- 冯诺依曼机的基本工作方式是控制流驱动的方式,也就是按照指令的执行序列,依此读指令……
- 预处理-编译-汇编-链接
- 给出一个64K*32位的存储器
=>数据总线:32位,地址总线:16位
=>MAR:16位,MBR:32位 - 字!=字长
第二章:数据的表示和运算
- 通常用补码整数表示整数,用原码小数表示浮点数的位数部分,用移码表示浮点数的阶码部分
- 扩展:原数字是无符号整数,进行零扩展;是有符号整数,用符号扩展。
关于数制转换:
任何一个q进制数字都可以唯一表示成这样的形式:
所谓:“除基取余,先余为低,后余为高”,“乘基取余,先整为高,后整为低”
都是在操作上边的那个公式,这里可以把各种各样数制的数都视为一个量,在进行不同的进制转换的时候,
就是在选择一个特定的模数去计算公式中的系数,用那些口诀进行转换时,是因为我们希望在个位看到并记录对应转换后的系数,所以十进制转成二进制时的整数部分->“除基”,小数部分->“乘基”,实际上是在加和减公式中q的指数,让我们希望看到的结果出现在个位被记录。所谓“先后”,就是通过观察得到的系数顺序来判断在新的数制下的位置。
{kind=link}
不同进制间的转换都类似这样,可以通过十进制做中转,无论怎么变,数都是一个量,量是不变的,变的是表示方式/拆分方式
关于编码转换:
转换方式:按位取反后再加一 = 减一后再按位取反
( - X + 1 ) = - ( X - 1 )
在补码系统内的转换
eg:[X_补]->[-X_补],全部数位按位取反+1
在原码系统和补码系统之间的转换
原码->补码:
如果是正数:原码=反码=补码
如果是负数:除了符号位不变,按位取反后再加一
判断溢出:
只要参加操作的两个数的符号相同,结果又与原操作数的符号不同,则表示结果溢出
对于无符号数字:进位意味着溢出
对于有符号数字:进位对于溢出及不充分也不必要
关于浮点数
注意:用原码小数表示的浮点数的尾数部分,其符号位被单另取出放在符号位
IEEE 754规定:单精度浮点数的偏置是127;尾数最高位的“1”是被隐藏的。
第三章:存储系统
磁盘不是ROM!!!ROM与RAM共同构成主存的地址域
从CPU的角度看,Cache-主存层的速度接近于Cache,容量和价位却接近于主存
从主存-辅存层分析,其速度接近于主存,容量和价位却接近于辅存。
这解决了速度、容量、成本三者之间的矛盾CD-ROM——只读型光盘存储器,不是只读存储器ROM
DRAM一定采用地址复用技术
随机存取与随机存储器(RAM)是两个不同的概念,制度存储器(ROM)也是随机存取的。因此,支持随寄存器的存储器不一定是RAM。
扇区按固定圆心角度划分,因此位密度从最外道向里道增加,磁盘的存储能力受限于最内道的最大记录密度。
存取时间由寻道时间、旋转延迟时间、传输时间,三部分组成
全写法,当CPU对Cache命中时,必须把数据同时写入Cache和主存
回写法,当CPU对Cache命中时,只把数据写入Cache,而不立即写入主存
Cache行的位数 = 标记位+数据位(块内多少bit)虚拟存储器只能采用回写法、
主存和辅存共同构成了虚拟存储器。
实地址 = 主存页号 + 页内字地址
虚地址 = 虚存页号 + 页内字地址
辅存地址 = 磁盘号 + 盘面号 + 磁道号 + 扇区号
页表未命中意味着信息不在主存,因此Page缺失时,Cache也必然缺失
TLB只是页表的一部分副本,页表缺失,Cache也必然缺失
页式和段式均采用“页”,按逻辑分“段”
- 主存-外存层次通常采用全相联映射
第四章:指令系统
- 主存一般按字节编址,所以指令字长通常为字节的整数倍
- 一条指令包括操作码和地址码字段
- 扩展操作码指令格式:!不允许短码时长码的前缀
指令中的地址码字段并不代表操作数的真实地址,这种地址称为形式地址(A)
形式地址结合寻址方式,可以计算出操作数在存储器中的真实地址,这种地址称为有效地址(EA)
- 隐含寻址:这种类型的指令不明显地给出操作数的地址,而是隐含操作数的地址,约定第二个操作数由累加器(ACC)提供。
- 立即数寻址:指令字中的地址字段指出的不是操作数的地址,而是操作数的本身——立即数
- 直接寻址:指令字中的形式地址A就是操作数的真实地址EA,EA=A
- 间接寻址:指令的地址字段给出的不是操作数的真正地址,而是操作数有效地址所在主存单元的地址,EA=(A)
- 寄存器寻址:指令的地址字段给出的是操作数所在寄存器的编号,EA=R_i
- 寄存器间接寻址:综合间接寻址和寄存器寻址各自的特点,EA=(R_i)
- 相对寻址:EA=(PC)+A,基址寻址,变址寻址,堆栈寻址
第五章:中央处理器
计算机中的堆栈都是向低地址方向生长的
- 不论CPU内部结构多么复杂,它都可视为由数据通路和控制部件两大部分组成。
数据通路,将ALU和所有寄存器连接到一条内部总线上,称为单总线结构的数据通路 - 超线程(SMT):性能!= 两个CPU,是对实体双核的模拟
- UMA架构中所有CPU共享同一内存空间 ,每个CPU的Cache中都是共享内存中的一部分副本,因此各CPU的Cahce一致性是需要解决的重要问题
第六章:总线
- 分时和共享是总线的两个特点
- DMA总线用于在内存和告诉外设之间直接传输数据
总线的主要性能指标为总线宽度、总线工作频率、总线带宽
总线带宽=总线宽度*总线工作频率 - DMA请求的优先级高于中断请求
- 中断方式靠程序传送,DMA方式靠硬件传送
还有一些我们课程比较注重的考点:
总线仲裁方式
- 菊花链仲裁:借 “总线允许” 控制线,按设备优先级传递信号
- 集中式并行仲裁:控制器会形成性能瓶颈
- 基于自检测的分布式仲裁:由设备自身判定优先级
- 基于冲突检测的分布式仲裁:以太网使用这种类型的仲裁(CSMA)
有效访问时间-EAT的计算
有效访问时间=命中率×命中时间+失效率×失效惩罚
阿姆达尔定律
𝑆=1/(𝑓/𝑘+(1−𝑓))
f:优化的部分占总体性能的比例
k:优化的部分的加速比
S:系统的整体加速比
RAID
条带化技术就是将一块连续的数据分成很多小部分并把他们分别存储到不同的磁盘上去。
这就能使多个进程同时访问数据的多个不同部分而不会造成磁盘冲突。
RAID 0、3、4、5、6 使用了条带化技术
RAID 1、2 没有使用条带化技术。
RAID 2,3 按位划分数据
RAID 0,1,4,5,6按块划分数据
RAID2->RAID3:汉明码(效率低下)->奇偶校验码
RAID3->RAID4:按位存储->块级存储方式使得数据重建过程更加高效
RAID4->RAID5:单盘存储校验信息(性能瓶颈)->校验信息分散
I/O控制方法
- 程序控制I/O
- 中断控制I/O
- 存储器映射I/O
受保护的环境
- 虚拟机
- 子系统
- 逻辑分区(与磁盘分区不同,磁盘分区还是一个设备)
编译过程
- 绝对代码:
实际内存地址在程序编译时确定, - 可重定位代码:
实际内存地址由操作系统在操作系统加载时确定
地址绑定
编译时地址绑定:绝对代码(absolute code)
加载时地址绑定:可重定位代码(relocate code)
运行时内存绑定:动态绑定(dynamic binding)
(编译时静态链接,加载/运行时动态链接)
嵌入式设备
- 标准处理器
- 可重构处理器
- 全定制处理器
微控制器:看门狗计时器
可编程逻辑设备:PAL,PLA,FPGA
支持指令级并行的架构
- 流水线
- 超标量
- 向量机
超长指令字(VLIW)依赖编译器在编译时安排指令的并行执行,热不是在运行时动态调度。