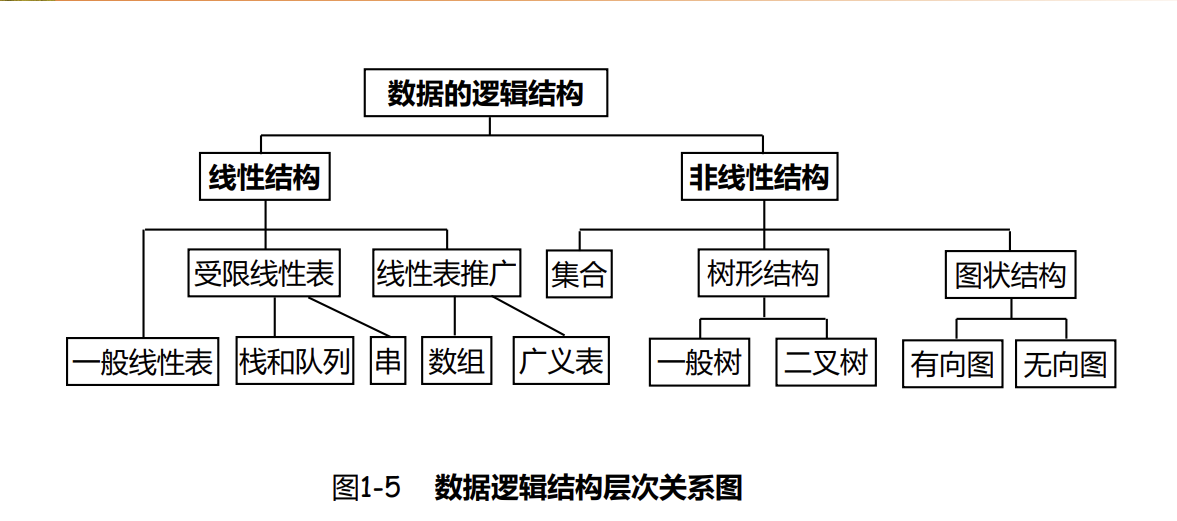
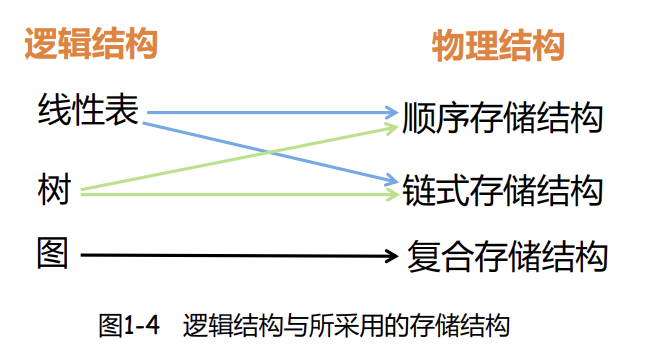
参考: https://github.com/callmePicacho/Data-Structres/blob/master/README.md
[SCU练习平台题解]课堂练习 练习 NO1,最大子列和问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <bits/stdc++.h> using namespace std;int Max3 (int A,int B,int C) return A > B ? A > C ? A : C : B > C ? B : C;int DivideAndConquer (int List[],int left ,int right) int MaxLeftSum,MaxRightSum;int MaxLeftBorderSum,MaxRightBorderSum;int LeftBorderSum,RightBorderSum;int center,i;if (left == right)if (List[left] > 0 )return List[left];else {return 0 ;2 ;DivideAndConquer (List,left,center);DivideAndConquer (List,center+1 ,right);0 ,LeftBorderSum = 0 ;for (i = center;i >= left;i --){if (LeftBorderSum > MaxLeftBorderSum)0 ,RightBorderSum = 0 ;for ( i = center + 1 ;i <= right; ++ i)if (RightBorderSum > MaxRightBorderSum)return Max3 ( MaxLeftSum,MaxRightSum,MaxLeftBorderSum+MaxRightBorderSum);int MaxSubseqSum3 (int List[],int N) return DivideAndConquer (List,0 ,N-1 );
这题非常经典,分治法当然不是最好的。 “在线算法”实际上是贪心的方法,另一种办法是动态规划
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <bits/stdc++.h> using namespace std;int dp[100005 ];int main () int t;cin >> t;for (int k = 1 ;k <= t;++ k)int n;cin >> n;for (int i = 1 ;i <= n;++ i)cin >> dp[i];int start = 1 ,end = 1 ,p = 1 ;int maxsum = dp[1 ];for (int i = 2 ;i <= n;++ i){if (dp[i-1 ] + dp[i] >= dp[i])-1 ] + dp[i];else p = i;if (dp[i] > maxsum)printf ("%d\n" ,maxsum);return 0 ;
但是时间复杂度是O(n*m)肯定会超时,考虑使用单调队列进行优化:
<div class="fold"> <div class="fold-title fold-info collapsed" data-toggle="collapse" href="#collapse-0ad24a9b" role="button" aria-expanded="false" aria-controls="collapse-0ad24a9b"> <div class="fold-arrow">▶</div>动态规划+前缀和+单调队列 </div> <div class="fold-collapse collapse" id="collapse-0ad24a9b"> <div class="fold-content"> 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <bits/stdc++.h> using namespace std;int > dq;int s[100005 ];int main () int n,m;scanf ("%d%d" ,&n,&m);for (int i = 1 ;i <= n;++ i)scanf ("%lld" ,&s[i]);for (int i = 1 ;i <= n;++ i)s[i] = s[i] + s[i-1 ];int ans = -1e8 ;push_back (0 );for (int i = 1 ;i <= n;++ i)while (!dq.empty ()&&dq.front () < i - m)dq.pop_front ();if (dq.empty ())ans = max (ans,s[i]);else ans = max (ans,s[i] - s[dq.front ()]);while (!dq.empty () && s[dq.back ()] >= s[i])dq.pop_back ();push_back (i);return 0 ;
NO2,多项式的加法和乘法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 #include <bits/stdc++.h> using namespace std;#define maxn 10010 int a[maxn+1 ];int b[maxn+1 ];int c[maxn+1 ];int d[maxn+1 ];void getmul () int flag = 0 ;for (int i = 0 ;i <= maxn;++ i)if (a[i] != 0 )for (int j = 0 ;j <= maxn;++ j)if (b[j] != 0 )int mark = 0 ;for (int i = 0 ;i <= maxn;++ i)if (d[i] != 0 )break ;for (int i = maxn;i >= 0 ;i --)if (d[i] != 0 )1 ;" " << i << " \n" [i==mark]; if (flag == 0 )"0 0" << endl;void getsum () int flag = 0 ;for (int i = 0 ;i <= maxn;++ i)int mark = 0 ;for (int i = 0 ;i <= maxn;++ i)if (c[i] != 0 )break ;for (int i = maxn;i >= 0 ;i --)if (c[i] != 0 )1 ;" " << i << " \n" [i == mark]; if (flag == 0 )"0 0" << endl;int main () int num1,num2;while (num1--)int x,y;while (num2--)int x,y;getmul ();getsum ();return 0 ;
4 数组×40044 字节/数组=160176 字节 这大约是 156.5 KB。 这样虽然过了,但是没考虑过空间浪费。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 #include <bits/stdc++.h> using namespace std;#define maxn 10010 typedef struct LNode *List;struct data {int x;int y;struct LNode {struct data Data[maxn]; int Last;List init () malloc (sizeof (struct LNode));-1 ;return L;void insert (int x,int y,List L) return ;void getsum (List L1,List L2) int pointer1 = 0 ;int pointer2 = 0 ;while (pointer1 <= L1->Last && pointer2 <= L2->Last)if (L1->Data[pointer1].y > L2->Data[pointer2].y)printf ("%d %d " ,L1->Data[pointer1].x,L1->Data[pointer1].y);else if (L1->Data[pointer1].y < L2->Data[pointer2].y)printf ("%d %d " ,L2->Data[pointer2].x,L2->Data[pointer2].y);else {printf ("%d %d " ,L1->Data[pointer1].x + L2->Data[pointer2].x,L1->Data[pointer1].y);if (pointer1 <= L1->Last)printf ("%d %d " ,L1->Data[pointer1].x,L1->Data[pointer1].y);else if (pointer2 <= L2->Last)printf ("%d %d " ,L2->Data[pointer2].x,L2->Data[pointer2].y);int main () int num1,num2;init ();while (num1--)int x,y;insert (x,y,L1);init ();while (num2--)int x,y;insert (x,y,L2);printf ("\n" );getsum (L1,L2);return 0 ;
这段中尝试使用了动态数组实现顺序表的办法,完成了多项式加法
优势:相比上一份静态数组,处理数据时拿多少用多少。比如同样一组输入,空间占用从165kB降至不到100B。 缺点:虽然实现,但是代码中有几个问题: 1.在线算法,算一条输出一条,不灵活,这也解释了为什么乘法部分没有继续写。更好的做法是再开一个数组存答案。 2.输出部分未封装,题目部分有格式要求,较复杂的输出适合单独封装一个函数做输出。 3.空间连续,这是开数组和开链表的重要区别:数组空间必须物理上连续,而实际上计算机内存物理上并不连续,你以为的连续实际上是操作系统给出的抽象层,造成了空间连续的假象(逻辑上连续),这就会在要求比较苛刻的情况中浪费空间。 Tips:看懂一份代码不难,重要的是如何独立写出来。一个好办法是阅读注释,注释和编写过程中的调试遗迹是好东西,编写边调试即可化难为简。 可惜的是,大多数题解将调试遗迹删去。
最优解法:链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 #include <stdio.h> #include <stdlib.h> typedef struct Node *List;struct Node {int z; int x; List Read () {malloc (sizeof (struct Node));int n;int i=0 ;scanf ("%d" ,&n);for (i=0 ;i<n;i++){int x;int z;malloc (sizeof (struct Node));scanf ("%d %d" ,&x,&z);NULL ;return head->Next;List addition (List L1,List L2) {malloc (sizeof (struct Node));NULL ;while (tmpL1 && tmpL2){malloc (sizeof (struct Node));if (tmpL1->z == tmpL2->z){ else if (tmpL1->z < tmpL2->z){ else if (tmpL2->z < tmpL1->z){ if (tmpL1) else if (tmpL2) return head->Next; List multiplication (List L1,List L2) {malloc (sizeof (struct Node));NULL ;for (;tmpL1;tmpL1=tmpL1->Next)for (tmpL2 = L2;tmpL2;tmpL2=tmpL2->Next){malloc (sizeof (struct Node));NULL ;addition (t,mul); return head;void Print (List L) int flag = 1 ;for (;t;t = t->Next){if (!flag && t->x) printf (" " );if (t->x){ printf ("%d %d" ,t->x,t->z);0 ; if (flag)printf ("0 0" );printf ("\n" );int main () Read ();Read ();addition (L1,L2);multiplication (L1,L2);Print (mul);Print (add);return 0 ;
0908NO3,树的同构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <iostream> #include <malloc.h> #define null -1 using namespace std;struct TreeNode {char data; int left; int right; 10 ],T2[10 ];int create (struct TreeNode T[]) int n;int root = 0 ;char left,right;if (!n)return null;for (int i=0 ;i<n;i++){if (left=='-' )else {'0' ;if (right=='-' )else {'0' ;return root;bool judge (int R1,int R2) if (R1 == null && R2 == null) return true ;if (R1 == null && R2 != null || R1 != null && R2 == null) return false ;if (T1[R1].data != T2[R2].data) return false ;if ((T1[R1].left != null && T2[R2].left != null )&&(T1[T1[R1].left].data == T2[T2[R2].left].data)) return judge (T1[R1].left,T2[R2].left) && judge (T1[R1].right,T2[R2].right);else return judge (T1[R1].right,T2[R2].left) && judge (T1[R1].left,T2[R2].right);int main () int R1,R2;create (T1);create (T2);if (judge (R1,R2))"Yes" ;else "No" ;return 0 ;
之后的笔记就是关于大二下左老师算法设计课程。
Week2: 之前讲了完整的时间复杂度分析理论。这节课承接上文:
我们现代的普通计算机计算能力是每秒1亿次,10^9,当一个问题的计算规模超过10^13,一万亿次时,我们认为一般是不可接受的。
▶
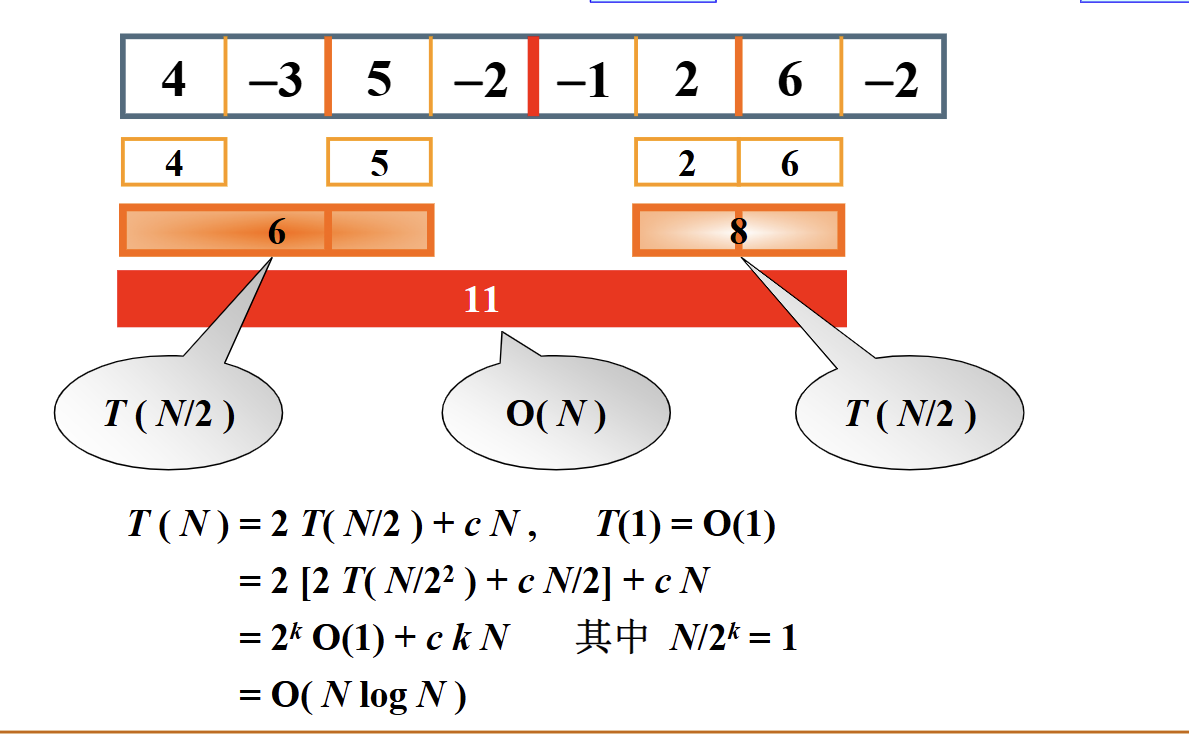
为什么排序问题的最优时间复杂度是nlog(n)?
要理解为什么排序问题的最优时间复杂度是 ( \Omega(n \log n) ),我们需要考虑基于比较的排序算法的性质。基于比较的排序算法是那些仅通过比较元素来确定它们的顺序的算法。这些算法的最优时间复杂度由决策树模型来确定。
逐步解释: 决策树模型 :
在决策树模型中,每个内部节点代表两个元素之间的比较,每个叶节点代表可能的排序结果。 对于 ( n ) 个元素,有 ( n! )(n的阶乘)种可能的排列。因此,决策树必须至少有 ( n! ) 个叶节点。 树的高度 :
二叉树的高度是最大的路径长度从根到叶。在决策树中,高度代表最坏情况下的比较次数。 一个有 ( n! ) 个叶节点的二叉树的高度至少是 ( \log_2(n!) )。 斯特林近似 :
斯特林近似表明 ( n! \approx \sqrt{2 \pi n} \left( \frac{n}{e} \right)^n )。 使用这个近似,我们可以估计 ( \log_2(n!) \approx \log_2 \left( \sqrt{2 \pi n} \left( \frac{n}{e} \right)^n \right) )。 简化对数 :
( \log_2(n!) \approx \log_2 \left( \sqrt{2 \pi n} \right) + \log_2 \left( \left( \frac{n}{e} \right)^n \right) ) ( \log_2(n!) \approx \frac{1}{2} \log_2(2 \pi n) + n \log_2 \left( \frac{n}{e} \right) ) ( \log_2(n!) \approx \frac{1}{2} \log_2(2 \pi n) + n \log_2(n) - n \log_2(e) ) 主导项 :
当 ( n ) 变得很大时,项 ( n \log_2(n) ) 主导表达式。 因此,( \log_2(n!) \approx n \log_2(n) )。 结论 :
由于决策树的高度至少是 ( \log_2(n!) ),并且 ( \log_2(n!) \approx n \log_2(n) ),任何基于比较的排序算法在最坏情况下的比较次数至少是 ( n \log_2(n) )。 这意味着基于比较的排序算法的最优时间复杂度是 ( \Omega(n \log n) )。
之后还讲了递归算法的时间复杂度分析。
“这块东西你们其实以前也见过了,但是没有经过一个系统的学习,产生一个本质的了解。通过这两节课让大家对这个有一个本质的了解。”
递归与其说是一种算法,不如说是一种思维方式。(与数学归纳法类似的想法)
Week3: Week4: Week5: Week6: Week7: Week8: Week9: Week10: 矩阵的乘法次数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> using namespace std;int n;int q[110 ];int dp[110 ][110 ];int solve (int i, int j) if (i == j) {0 ;return 0 ;if (dp[i][j] != -1 ) return dp[i][j];int m = INT_MAX;for (int k = i; k < j; k++) {int cost = solve (i, k) + solve (k+1 , j) + q[i-1 ] * q[k] * q[j];if (cost < m) m = cost;for (int s = 1 ;s <= 10 ;s ++ ){for (int t = 1 ;t <= 10 ;t ++){" \n" [t==10 ];return m;int main () scanf ("%d" , &n);for (int i = 0 ; i <= n; i++) {memset (dp, -1 , sizeof dp);printf ("%d" , solve (1 , n));return 0 ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include <iostream> using namespace std;const int N = 100 ;int A[N];int m[N][N];int s[N][N];void MatrixChain (int n) int r, i, j, k;for (i = 0 ; i <= n; i++)0 ;for (r = 2 ; r <= n; r++)for (i = 1 ; i <= n - r + 1 ; i++)1 ;1 ][j] + A[i - 1 ] * A[i] * A[j];for (k = i + 1 ; k < j; k++)int t = m[i][k] + m[k + 1 ][j] + A[i - 1 ] * A[k] * A[j];if (t < m[i][j])void print (int i, int j) if (i == j)"A[" << i << "]" ;return ;"(" ;print (i, s[i][j]);print (s[i][j] + 1 , j);")" ;int main () int n;int i, j;for (i = 0 ; i <= n; i++)MatrixChain (n);"最佳添加括号的方式为:" ;print (1 , n);"\n最小计算量的值为:" << m[1 ][n] << endl;return 0 ;
Week11: Week12: Week13: Week14: Week15: Week16: